Method
Telescopic Adapter Framework
The core insight is a depth-aware telescopic scaling strategy: rather than applying uniform adapter widths, we assign smaller bottleneck dimensions to early layers and progressively increase capacity toward deeper layers.
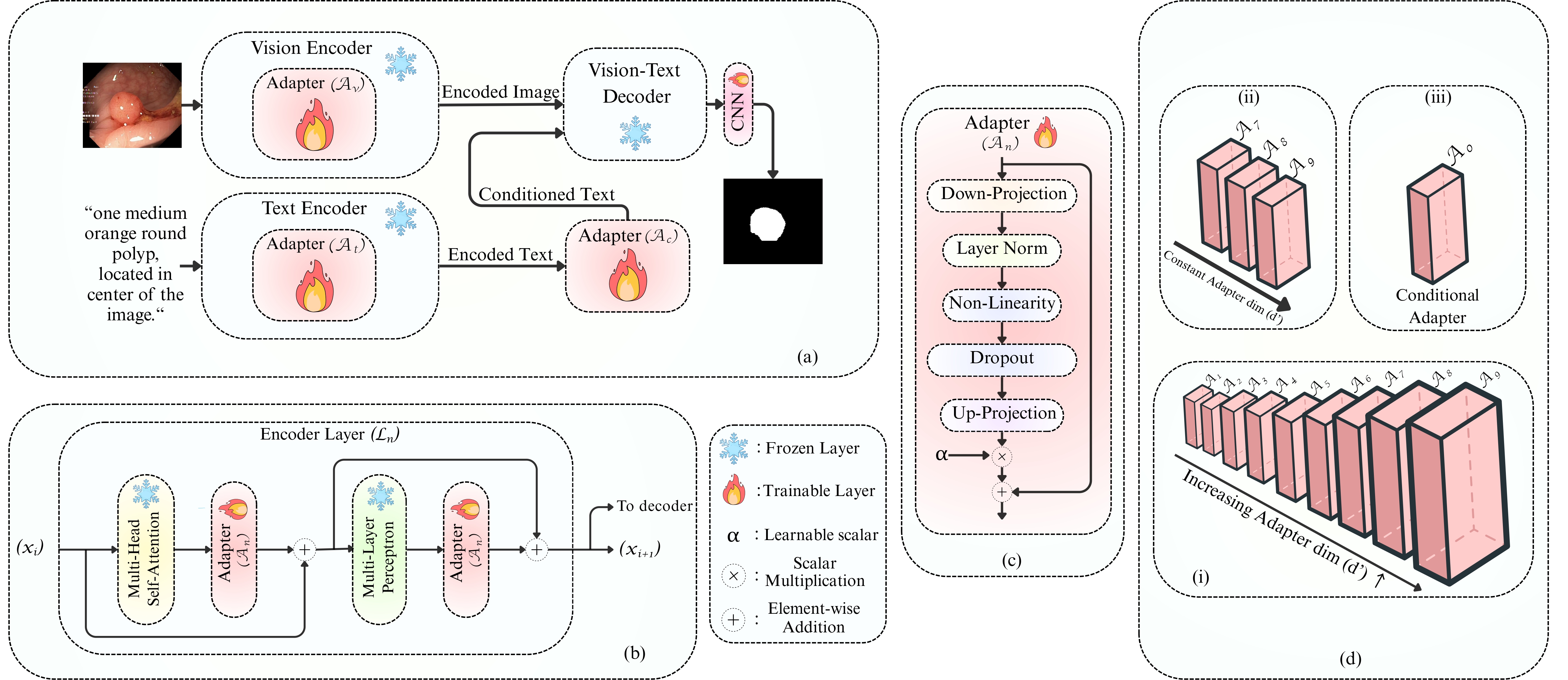
Figure 1. Overview of the proposed telescopic adaptation framework highlighting depth-aware dimension allocation across vision and text branches.